python实践:利用爬虫刷网课
利用爬虫刷网课
用过python的人应该都会知道爬虫这个东西,网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
今天就来讲讲如何利用爬虫技术刷网课。
最近学校又推送了一波网课,一个一个的看实在太费时间,于是乎就想到了爬虫来自动刷网课。
分析网站源代码,看看网站是如何上传用户的数据的。
这是我们的主站
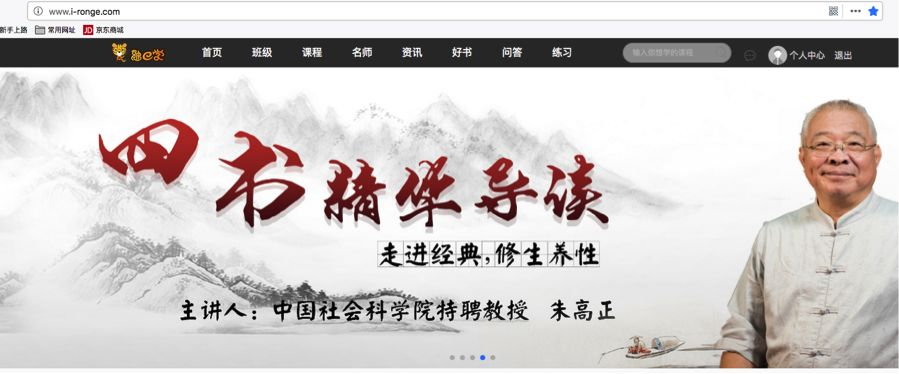
这是我们要刷的课程
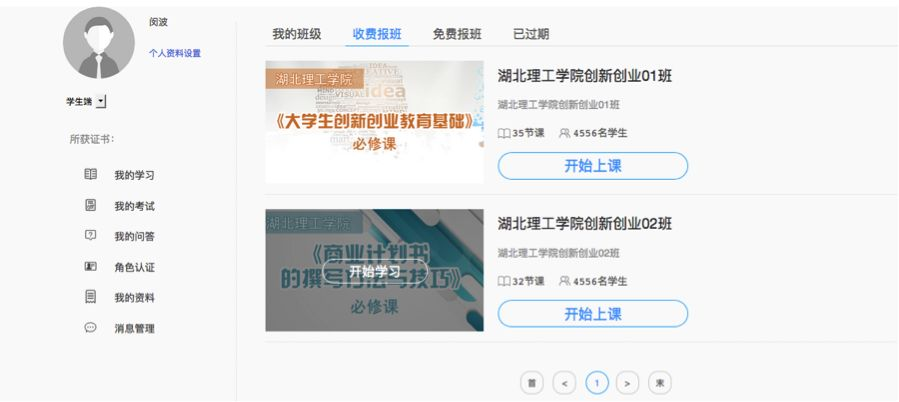
接下来就开始分析源代码了哦,

这个就是播放视频相关的js代码。
我们点进去找找播放之后上传相关的函数。

从这个javascript函数我们可以看到这个是播放完毕以后上传到服务器的json数据包。
我们只需要两个参数就可以实现这个函数的重放了。
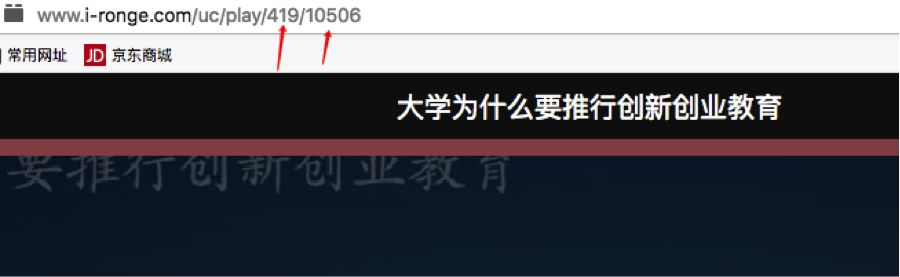
courseId就是url里面的419
couttentkpointId就是url里面的10506
每个视频的pointid不一样,我们只需要for循环遍历就行了。
接下来我们就需要看看这个网站是如何登录的了。
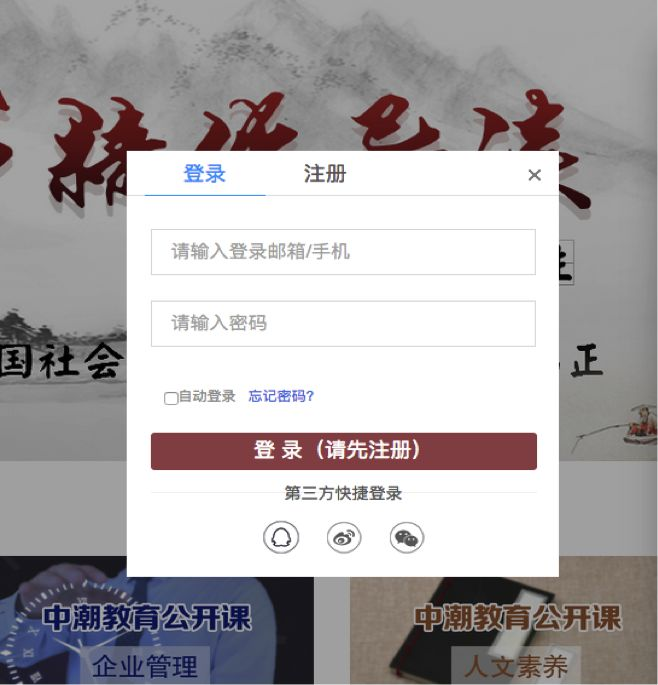
看到没,这个网站连验证码都没有,模拟登录就是小儿科了。
打开我们的brup suite抓个包看看,当然也可以不需要抓包,直接分析源代码就可以,照顾一下新手,我们就来抓个包吧。
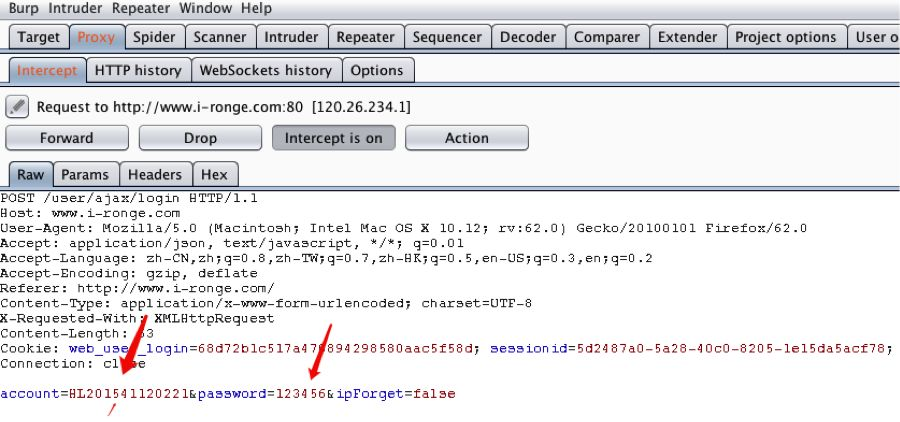
从这里我们就可以看到这是一个POST方法,三个参数分别是account,password,ipForget。
好的接下来我们就用python来模拟登陆了。
首先在终端下面安装一下requests。我的系统是mac os
这个是已经安装好了的,没有安装就安装一下,windows是需要先安装python的。这里我就不讲如何安装了。
然后打开我们的代码编辑器。我这里用的是sublime.
代码如下:
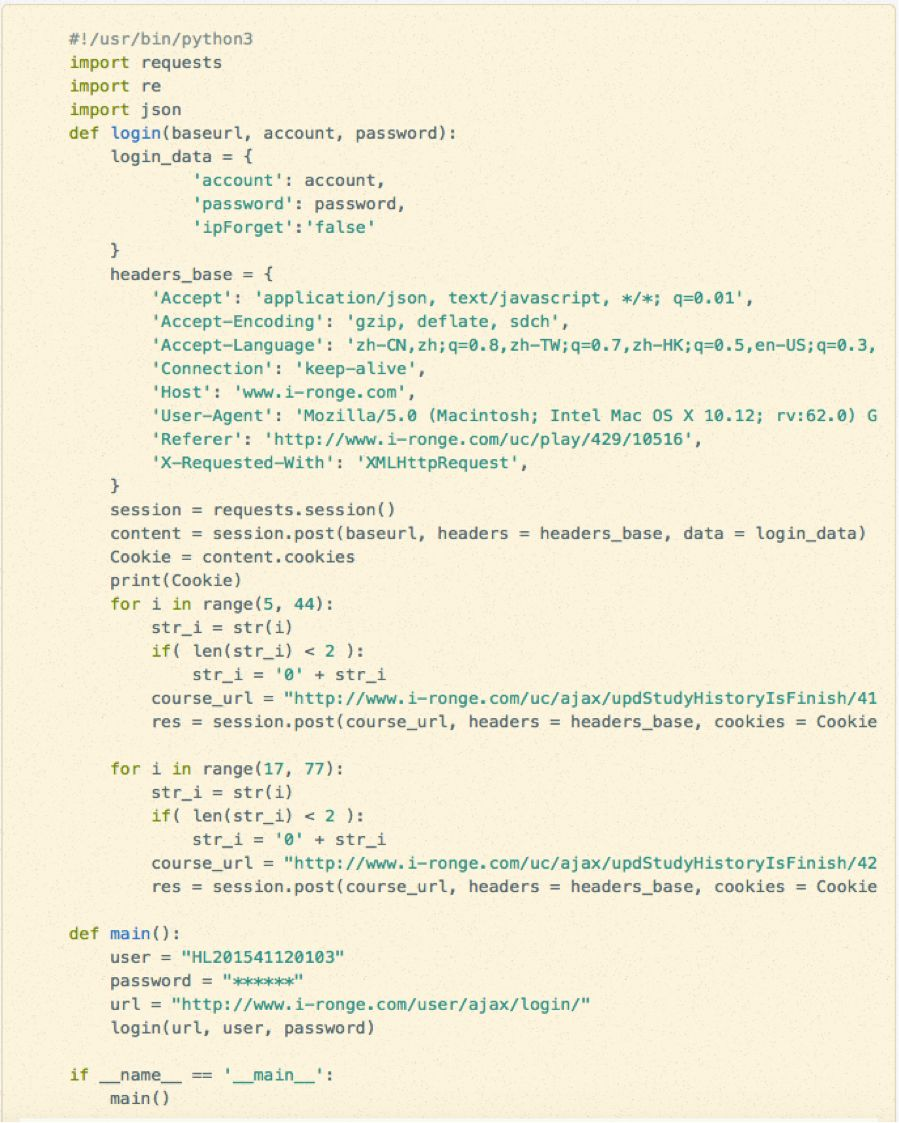
首先就是一个登陆,登陆之后我们就有了cookie,然后利用这个cookie来发包刷网课就行了。
这个网站还是存在很多问题的,如何登陆缺乏验证就可快速爆破,在笔记的地方存在xss漏洞,具体分析过程我在这里就不写了。谢谢大家。
更多内容请访问:https://blog.123wk.top/
本站提供的所有下载文件均为网络共享资源,请于下载后的24小时内删除。如需体验更多乐趣,还请支持正版。
我站提供用户下载的所有内容均转自互联网,如有内容侵犯您的版权或其他利益的,请编辑邮件并加以说明发送到站长邮箱,站长会进行审查之后,情况属实的会在三个工作日内为您删除。
小没源码网 » python实践:利用爬虫刷网课